

新媒易动态
NEWS CENTER

NEWS CENTER
2019-11-04
需要收集的数据主要能划分成四个主要类型:行为数据、网站日志数据、业务数据、外部数据。
网站日志数据是Web时代的概念。
用户浏览的每一个网页,都会向服务器发送请求,具体的技术细节不用关注。只要知道,当服务器和用户产生数据交互,服务器就会把这次交互记录下来,我们称之为日志。
127.0.0.1 – – [20/Jul/2017:22:04:08 +0800] “GET /news/index HTTP/1.1” 200 22262 “-” “Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.66 Safari/537.36”
上图就是一条服务器日志,它告诉了我们,什么样的用户who在什么时间段when进行了什么操作what。
127.0.0.1是用户IP,即什么样的用户。不同用户的IP并不一致,通过它能基本的区分并定位到人。[20/Jul/2017:22:04:08 +0800] 是产生这条记录的时间,可以理解为用户访问的时间戳。
“GET /news/index HTTP/1.1″是服务器处理请求的动作,在这里,姑且认为是用户请求访问了某个网站路径,/news/index。这里省略了域名,如果域名是www.aaa.com,那么用户访问的完整地址就是www.aaa.com/news/index,从字面意思理解,是用户浏览了新闻页。也就是what。
who、when、what构成了用户行为分析的基础。Mozilla/5.0这个字段是用户浏览时用的浏览器,它的分析意义不如前三者。
如果我们基于who分析,可以得知网站每天的PVUV;基于when分析,可以得知平均浏览时长,每日访问高峰;what则能得知什么内容更吸引人、用户访问的页面深度、转化率等属性。
上面的示例中,我们用IP数据指代用户,但用户的IP并不固定,这对数据口径的统一和准确率不利。实际应用中还需要研发们通过cookie或token获取到用户ID,并且将用户ID传递到日志中。它的形式就会变成:
127.0.0.1 – 123456 [20/Jul/2017:22:04:08 +0800]…
123456就是用户ID,通过它就能和后台的用户标签数据关联,进行更丰富维度的分析。
案例的服务器日志,记录了用户的浏览数据,是标准的流量分析要素。但是网站上还会有其他功能,即更丰富的what,譬如评论、收藏、点赞、下单等,要统计这些行为靠日志就力有未逮了。所以业内除了服务器日志,还会配合使用JS嵌入或者后台采集的方式,针对各类业务场景收集数据。
在这里我提供一份网上公开的数据集,年代比较古老,是学生在校园网站的浏览行为数据集。数据原始格式是log,可以txt打开。需要的同学可以在后台发送「日志下载」。
它是标准的服务器日志文件,对分析师来说,IP,时间、浏览了哪些网页,这三个字段足够做出一份完整的分析报告。后续的章节我将围绕它进行演练,为了照顾新手,会同时用Excel和Python演示。
首先进行简单的清洗。如果是Excel,直接将内容复制,文件开头的内容只需要保留第四行Fields信息,它是数据的字段。将内容复制黏贴到Excel中。
按空格进行分列,初步的数据格式就出来了。
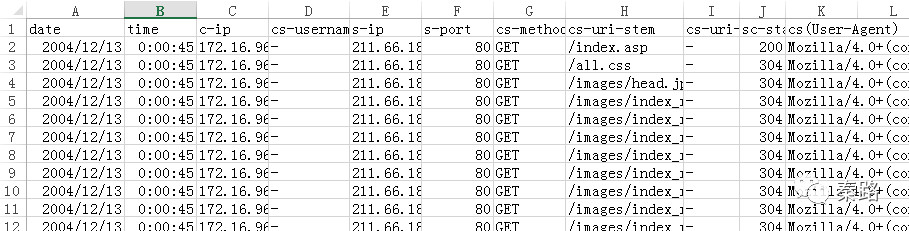
我们仔细观察cs-uri-stem,会发现有很多无用数据。比如/images/index_r2_c1.jpg,它是向服务器请求了图片数据,对我们分析其实没有多大帮助。用户访问的具体网页,是/index.asp这类以.asp为结尾的。
利用过滤功能,将含有.asp字符串的内容提取出来,并且只保留date、time、c-ip、cs-uri-stem、cs-uri-stem。按c-ip和time按从小到大排序,这样用户在什么时间做了什么的行为序列就很清晰了。
像172.16.100.11这位游客,在凌晨30分的时候访问了网站首页,然后浏览了校园新闻和一周安排相关的内容,整个会话持续了半小时左右的时间。
Python相关的清洗留待下一篇文章,这里就不多花时间讲解了。感兴趣,大家可以先自行练习一下。
数据埋点,抽象理解便是记录用户在客户端的关键操作行为,一行数据便等于一条行为操作记录。点击「立即抢购」是,在文章页面停留5min是,发表文章评论是,进行退出登录操作是,视频网站首页看到了10条新视频的内容曝光也是…反必要的,我们都采集。
APP行为数据是在日志数据的基础上发展和完善的。虽然数据的载体是在APP端,但它同样可以抽象出几个要素:who、when、where、what、how。
who即唯一标识用户,在移动端,我们可以很方便地采集到user_id,一旦用户注册,就会生成新的user_id。
这里有一个问题,如果用户处于未登录状态呢?如果用户有多个账号呢?为了更好地统一和识别唯一用户,移动端还会采集device_id,通过手机设备自带的唯一标识码进行区分。
实际的生成逻辑要复杂的多,安卓和iOS不一样,device_id只能趋近于唯一、用户更换设备后怎么让数据继承,未登录状态的匿名账户怎么继承到注册账户,这些都会影响到分析的口径,不同公司的判断逻辑不一致,此处注意踩坑。
回到用户行为:
如果我们想知道用户的点赞行为,那么在用户点赞的时候要求客户端上报一条like信息即可。
如果只是到这里,还称不上埋点,因为点赞本身也会写入到数据库中,并不需要客户端额外采集和上报,这里就引入了全新的维度:how。
如何点赞,拿微信朋友圈举例。绝大部分的点赞都是在朋友圈timeline中发送,但是小部分场景,是允许用户进入到好友的个人页面,对发布内容单独点赞的。服务端/后台并不知道这个点赞在哪里发生,得iOS或安卓的客户端告诉它,这便是how这个维度的用处。
换一种思考角度,如果很多点赞或留言的发生场景不在朋友圈,而是在好友个人页。这是不是能讨论一下某些产品需求?毕竟朋友圈信息流内的内容越来越多,很容易错过好友的生活百态,所以就会有那么一批用户,有需要去好友页看内容的需求。这里无意深入展开产品问题,只是想说明,哪怕同样是点赞,场景发生的不同,数据描述的角度就不同了:朋友圈的点赞之交/好友页的点赞至交。
除了场景,交互行为方式也是需要客户端完成的。例如点击内容放大图片、双击点赞、视频自动播放、触屏右滑回退页面…产品量级小,这些细节无足轻重,产品变大了以后,产品们多少会有这些细节型需求。
行为埋点,通常用json格式描述和存储,按点赞举例:
params是嵌套的json,是描述行为的how,业内通常称为行为参数,event则是事件。action_type指的是怎么触发点赞,page是点赞发生的页面,page_type是页面的类型,现在产品设计,在推荐为主的信息流中,除了首页,还会在顶栏划分子频道,所以page=feed,page_type=game,可以理解成是首页的游戏子频道。item_id指对哪篇具体的内容点赞,item_type是内容类型为视频。
上述几个字段,就构成了APP端行为采集的how和what了。如果我们再考虑的齐全一些,who、when及其他辅助字段都能加上。
埋点怎么设计,不是本篇文章的重点(实际上也复杂的多,它需要很多讨论和文档and so on,有机会再讲),因为各家公司都有自己的设计思路和方法,有些更是按控件统计的无痕埋点。如果大家感兴趣,可以网络上搜索文章,不少卖用户分析平台的SaaS公司都有文章详细介绍。
除了行为「点」,埋点统计中还包含「段」的逻辑,即用户在页面上停留了多久,这块也是客户端处理的优势所在,就不多做介绍了。
这里提供一份来源于网上的我也不知道是啥内容产品的行为数据源,虽然它的本意是用作推荐模型的算法竞赛,不过用作用户行为分析也是可以的。